
顺藤摸瓜找到 Greg Kamradt 对 GPT-4-128K 的 128K Token 上下文回忆能力进行了压力测试。一些关键结论:
1. Prompt 中的开头和结尾是最关键的,尤其是结尾部分;
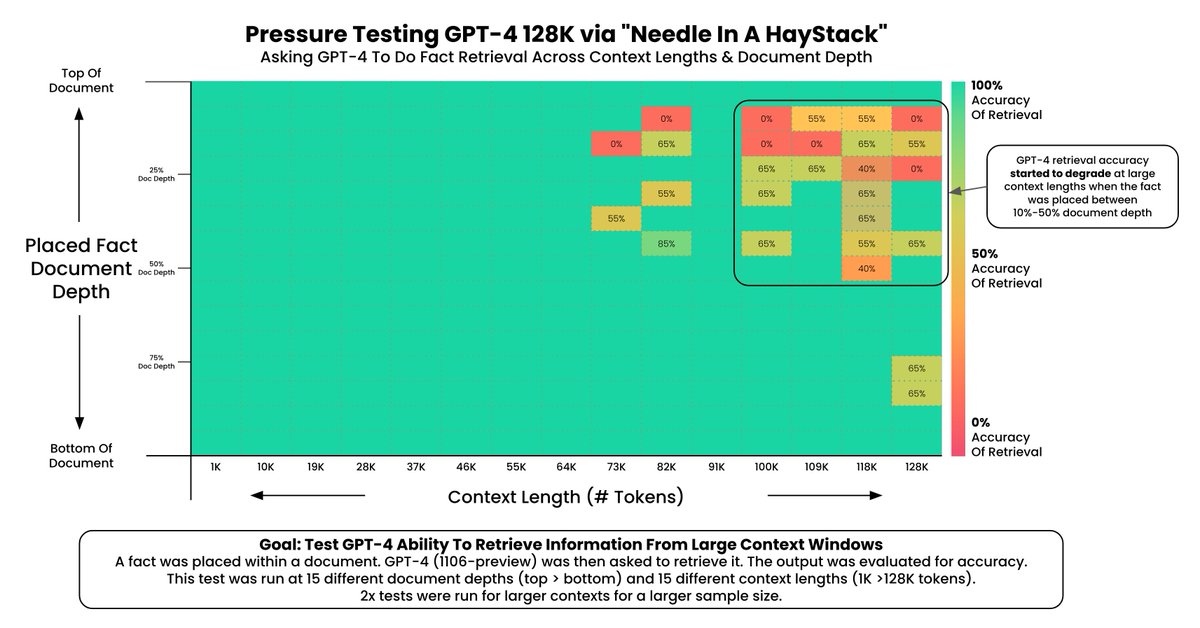
2 .位于中间 7%-50% 区间的内容效果最差
3. 上下文越少,准确性越高,超过 73K Token 时,GPT-4-128K 的记忆性能开始下降。…
IT技术
(
twitter.com
)
顺藤摸瓜找到 Greg Kamradt 对 GPT-4-128K 的 128K Token 上下文回忆能力进行了压力测试。一些关键结论:
1. Prompt 中的开头和结尾是最关键的,尤其是结尾部分;
2 .位于中间 7%-50% 区间的内容效果最差
3. 上下文越少,准确性越高,超过 73K Token 时,GPT-4-128K 的记忆性能开始下降。
以下是作者的原文:
用长篇幅上下文考验 GPT-4-128K 的记忆力
128K Token 的上下文听起来很厉害,但它的实际表现怎样呢?
为了找出答案,我进行了一项“大海捞针”的分析。
发现了一些意料之中和意料之外的结果。
我的发现如下:
**发现:**
* 超过 73K Token 时,GPT-4 的记忆性能开始下降。
* 当需要回忆的信息位于文档深度的 7%-50% 区间时,回忆表现较差。
* 如果信息位于文档开头,无论上下文有多长,它总能被记住。
**那么,这意味着什么?**
* 没有保证 - 你的信息不一定能被检索到。别指望你的应用程序能总是找到它们。
* 更少的上下文等于更高的准确性 - 这是常识,但如果可以的话,减少发送给 GPT-4 的上下文量可以提高其记忆准确性。
* 位置很关键 - 这也是常识,但放在文档开头和后半部分的信息似乎更容易被记住。
**分析过程概述:**
* 以 Paul Graham 的文章作为背景材料。有了 218 篇文章,轻松实现 128K Token。
* 在文档不同深度插入随机陈述。所用事实为:“在阳光明媚的日子里,在多洛雷斯公园吃三明治是在旧金山最佳活动。”
* 让 GPT-4 仅用提供的上下文来回答这个问题。
* 用 LangChainAI 的评估方法,再次用 GPT-4 对其答案进行评估。
* 对 15 种不同文档深度(从文档顶端的 0% 到底部的 100%)和 15 种上下文长度(1K Token 至 128K Token)进行重复测试。
**为了深入研究,接下来可以采取的步骤:**
* 尽管这些分析是均匀分布的,但有人建议用 sigmoid 分布可能会更好(这样可以在文档的开始和结束阶段发现更多细节)。
* 为了更严谨,应该进行键值对检索。但为了增加相关性,我在 Paul Graham 的文章中加入了关于旧金山的描述。
**备注:**
* 虽然我认为这些发现方向上是正确的,但需要更多测试来更深入地了解 GPT-4 的能力。
* 改变提示可能会改变结果。
* 在长上下文中进行了两次测试,以便更深入地挖掘性能。
* 这次测试大约花费了 200 美元用于 API 调用(单次调用 128K 输入 Token 的成本为 1.28 美元)。
* 感谢 Charles 🎉 Frye 提供意见和建议下一步的方向。
点击图片查看原图

