
OpenAI 开源的 Whisper 大模型, ASR (Automatic Speech Recognition)的问题,包括语音识别、翻译、VAD 检测等,其效果与各大厂收费的产品相比,不相上下,也算是作为一个搅局者加入到了整个市场。
云厂商识别 1 小时的语音,标价大概在 1~3…
IT技术
(
github.com
)
OpenAI 开源的 Whisper 大模型,https://t.co/bzcIgCoYRB,基本上解决了 ASR (Automatic Speech Recognition)的问题,包括语音识别、翻译、VAD 检测等,其效果与各大厂收费的产品相比,不相上下,也算是作为一个搅局者加入到了整个市场。
云厂商识别 1 小时的语音,标价大概在 1~3 元(参考国内云厂商计费),而 Whisper,最大的模型也就是 1.5B 参数(tiny 仅 39M,大小 ~1Gb),本地部署也就消耗下电费。
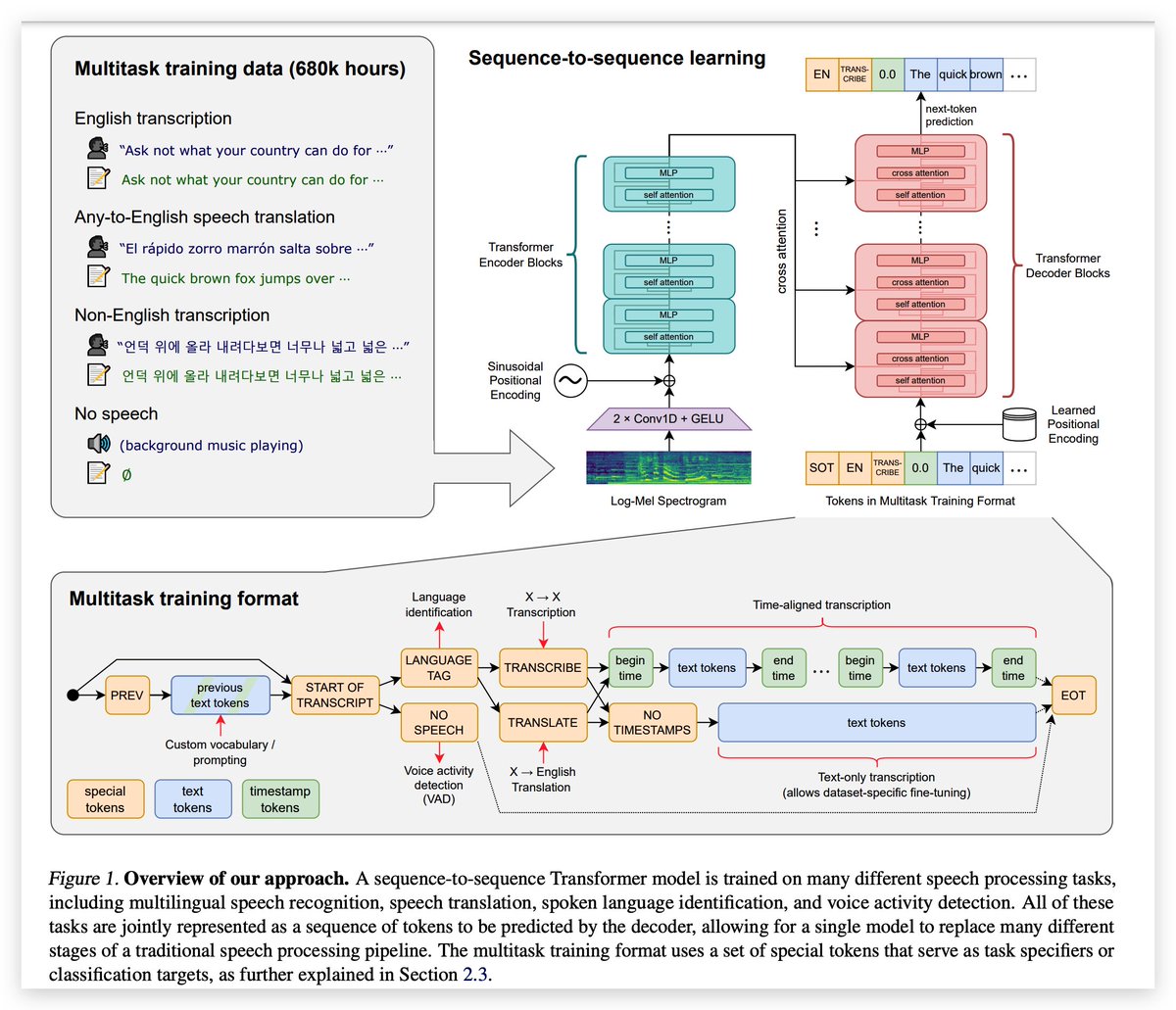
关于 Whisper 模型,《Robust Speech Recognition via Large-Scale Weak Supervision》,https://t.co/sidAah1kwb,这篇论文给出了详细的分析,从架构设计来看,它是一个标准的 Transformer encoder-decoder 架构,没有增加大的创新,之所以效果如此好,主打一个“大力出奇迹”。
它从互联网抓取了 68w 小时的数据进行训练,甚至都没有经历微调阶段和增强学习阶段,预训练模型默认好用。之前之所以没人这么干,是因为音视频数据一般都存在版权问题,要抓取 68w 小时如此庞大规模的数据量,很可能会涉及到了版权纠纷,另外,作者在论文也没有透露数据来源。当然,它公开了代码、训练过程和数据等情况,其有效性和价值是不可否认的。
这篇论文中提到,当前任务处理效果最好的是英语,基本上已经接近人类的水平(词错率 5.8%),但是在韩语、中文上,效果还是要差一些,仍有优化空间。更多详情可以听一听李沐在 B 站的《OpenAI Whisper 精读》,聊得比较有意思,https://t.co/UWaiWLdc2K
点击图片查看原图

