
重读 GraphRAG
微软 4 月发表 GraphRAG 后,7 月在 Github 也开源了代码方案。GraphRAG 也被寄予厚望能够成为 RAG 方向的终极形态,llamaIndex 也发布了结合 Neo4j 实现了 GraphRAG 的集成实现。
我想重新再读一遍 GraphRAG
时政
(
twitter.com
)
重读 GraphRAG @OpenAtMicrosoft
微软 4 月发表 GraphRAG 后,7 月在 Github 也开源了代码方案。GraphRAG 也被寄予厚望能够成为 RAG 方向的终极形态,llamaIndex @llama_index 也发布了结合 Neo4j @neo4j 实现了 GraphRAG 的集成实现。
我想重新再读一遍 GraphRAG 的论文、文档和代码实现,在理解了它的原理和实现架构后,再去看 GraphRAG 对现有 RAGs 可能的提升方向。
今天先从 GraphRAG 论文开始:
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
https://t.co/viI9QS9zdq
-----------------------------------
GraphRAG 是什么?
GraphRAG 是一种结构化、分层的 RAG 方法,与使用纯文本片段进行简单的语义搜索方法相比,它更为复杂。GraphRAG 的过程涉及从原始文本中提取知识图谱、构建社区层次结构、为这些社区生成摘要,并在执行基于 RAG 的任务时利用这些结构。
GraphRAG 有什么优势?
> 能够更好地回答 "全局问题" (涉及整个数据集的问题),而传统 RAG 方法在这方面表现不佳。
> 使用社区摘要和映射-归约方法来保留全局数据上下文中的所有相关内容。
GraphRAG 由什么组成?
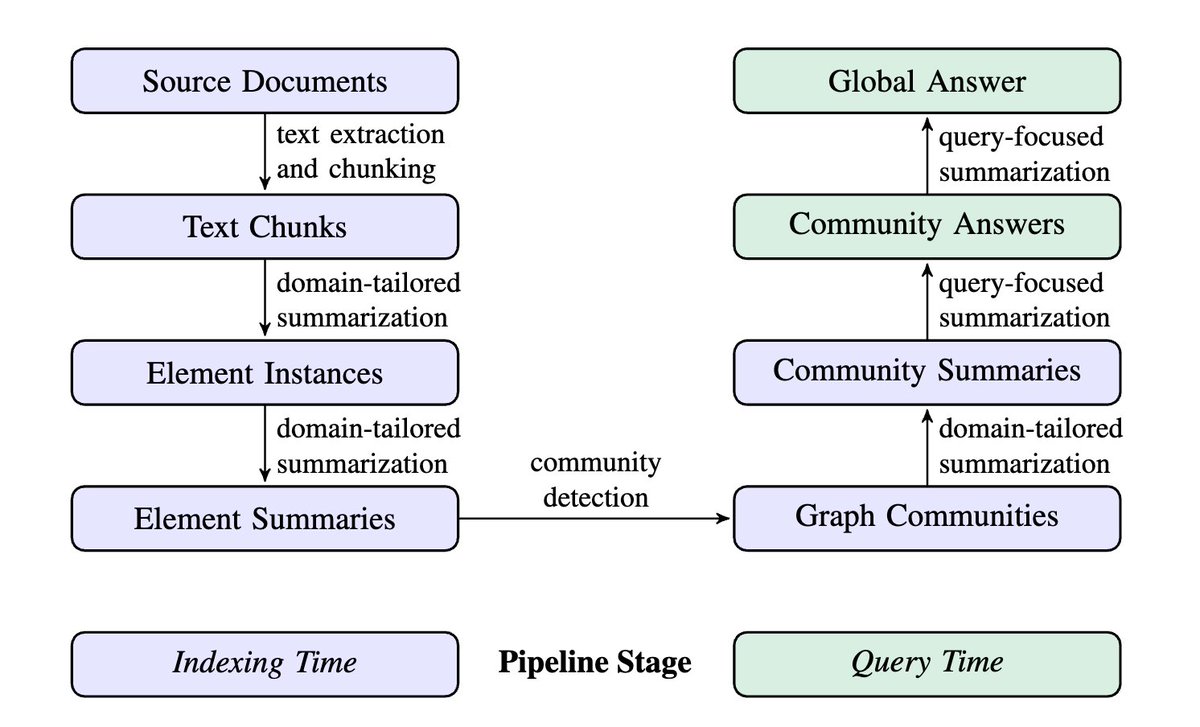
主要两个部分:Indexing 和 Query,其中又包含了不同的流程,协同完成一个完整的 GraphRAG 流程。
> 索引 (Indexing)
使用 LLM 从文本文档中自动提取丰富的知识图谱。
>> Source Documents → Text Chunks
处理源文档时将输入文本分割成合适大小的文本块是一个基本设计考量。更大的文本块虽能减少处理次数,但会影响提取信息的全面性。例如,使用较小的 600 标记文本块相较于较大的 2400 标记文本块,能够获得更多的实体引用,这在 HotPotQA 数据集的测试中得到了验证。然而,提取过程的目标是达到最佳的召回率和精确度,这就需要在两者之间做出权衡。
>> Text Chunks → Element Instances
LLM 用于从文本中提取实体、关系和声明的描述,实质上是抽象性总结,依赖模型理解文本未直接表述但隐含的概念。将实例级摘要转化为图元素描述需再经 LLM 汇总。尽管可能因实体引用格式不一致导致重复,但因后续步骤会检测并总结紧密关联的实体社区,且 LLM 能理解多变名字背后的同一实体,故整体方法能抵御此类变化。使用详尽描述文本符合 LLM 特性和全局查询摘要需求,区别于依赖简洁、一致性知识三元组的传统知识图谱。
>> Element Instances → Element Summaries
使用 LLM 从文本中抽取实体、关系和声明描述,本身就是一种抽象总结,依赖于 LLM 创建文本未明确提及但含义清晰的概念摘要。要将实例级摘要转换为图元素的描述性文本,需再通过 LLM 进行一轮汇总。尽管可能存在同一实体的多重引用导致重复节点的问题,但由于后续会检测并总结实体的关联社区,加上 LLM 能识别实体名变体下的共通实体,整体方法能容忍这种变体,前提是各变体间有足够联系。我们采用的丰富描述性文本适合LLM能力和全局查询聚焦摘要需求,区别于依赖简洁一致知识三元组的传统知识图谱,后者用于推理任务。
>> Element Summaries → Graph Communities
前一步生成的索引可视为加权无向图,实体节点通过关系边相连,边权重代表归一化的关系实例数。利用社区检测算法,可将图划分为节点社区,社区内的节点相互间联系更紧密。本流程采用 Leiden 算法,因其能有效恢复大规模图的层次化社区结构。层次中的每一级都以互斥且全包的方式提供社区划分,便于分而治之的全局摘要。
> 查询 (Query)
通过检测图中节点的"社区"来报告数据的语义结构,形成多层次的主题概述。
>> Graph Communities → Community Summaries
为了应对大型数据集,研究者为 Leiden 层次结构中的每个社区构建了报告摘要,这有助于用户理解数据集的整体架构和语义,即使在无特定查询时也能洞察语料库内容。用户可通过浏览摘要发现主题,并深入查看子主题细节。
摘要生成策略包括:
>>> 对叶级社区,依据节点重要性添加摘要至语言模型上下文直至满载;
>>> 对高级社区,若摘要总量适中则直接汇总,否则替换较长摘要以适应窗口限制。
这一过程的核心是利用社区摘要构建图索引,以有效回应宏观查询。
>> Community Summaries → Community Answers → Global Answer
用户查询后,先前生成的社区概要经多阶段处理形成最终答案。社区结构的层级特性允许利用不同层级的概要回答问题,引发探讨哪一层级最适于平衡概括详略与范围,利于综合理解。
具体步骤为:
>>> 随机打乱社区概要并分割成预设大小的片段,确保信息分散而非集中于单一视窗;
>>> 并行生成每段概要的中间答案,大型语言模型同时评分,0分答案被排除;
>>> 按评分降序整合中间答案至新视窗直至达上限,由此产生的最终视窗生成全球答案反馈给用户。
相关的技术讨论
> RAG 方法和系统
RAG 使用 LLM 时,首先从外部数据源检索相关信息,并将其添加到LLM的上下文窗口中,与原始查询一并处理。
Naive RAG 方法通过文档转文本、切分文本块和嵌入向量空间实现,其中相似语义对应相似位置,然后查询也被嵌入同一空间,最近的 k 个文本块作为上下文。
Advanced RAG 系统设计了预检索、检索和后检索策略来弥补朴素 RAG 的不足,而模块化 RAG 系统则采用迭代和动态循环检索生成模式。
Graph RAG 结合了多个系统的概念,如社区概要作为自我记忆用于增强检索,以及社区答案的并行生成类似于迭代或联邦检索-生成策略。其他系统也集成了这些概念进行多文档摘要和多跳问答。尽管如此,这些方法并未采用 Graph RAG 中所使用的自动生成的图索引。Graph RAG 的独特之处在于使用了能够自适应地对全局问题进行总结的图结构。
> Graphs 和 LLMs
在 LLMs 和 RAG 领域,图技术的应用正成为一个蓬勃发展的研究方向。研究者利用 LLMs 创建知识图谱和完成图谱填充,同时从文本中抽取因果关系图。此外,高级 RAG 技术也已出现,例如使用知识图谱作为索引的 KAPING 系统,以及通过图结构子集或基于图的度量来获取信息的 G-Retriever 和 GraphToolFormer 系统。还有些系统,比如 SURGE 和 FABULA,分别利用图结构事实构建叙事输出和串行化事件剧情子图;同时,也有系统支持创建和遍历文本关系图,以便进行多跳问答。
开源软件方面,LangChain 和 LlamaIndex 库支持多种图数据库,且正在发展中的基于图的 RAG 应用类别,包括能在 Neo4J 和 NebulaGraph 格式的知识图上创建和推理的系统。
然而,不同于我们的 Graph RAG 方法,这些系统均未利用图的自然模块化特性来对数据进行全球性概括。
点击图片查看原图

